LLM Reasoning Models comparison
自适应快慢思考推理模型(Adaptive Reasoning Model):Qwen3混合思考->字节AdaCoT->清华AdaThinking
1. 背景
OpenAI O 系列发布之后,Inference Time Scaling 的模型一直备受关注,这种具有长思考能力的模型倍称为:Large Reasoning Model(LRM)。所谓的长思考能力指得是 Long Chain-of-Thought(LongCoT),和大家在 Prompt Engeering 中常见的 CoT 技巧是一样的,比如告诉模型 Let's think it step-by-step 或者 You should think about it deeply before you give final answer,而 LongCoT 指的是模型可以输出【更长的思考过程】。
思考更长通常意味着更好的效果,但是也同样意味着推理耗时更长。但很显然,并不是所有的问题都需要模型进行很长的思考,就像人类处理问题一样,简单的东西可以快速回答,但是复杂的问题才需要打草稿进行更久的思考之后再给出回复。因此这种【快慢思考(fast-slow-thinking)】或者【混合思考(thinking-nonthinking mixed)】的方式成了业界新发力的方向。这样可以减少不必要的推理消耗而不损害模型的最终效果。
下面介绍三篇文章如何处理这种混合思考模式。
阿里巴巴通义实验室的 Qwen3 混合思考方式
字节跳动 Seed 提出的
AdaCoT的自适应(adaptive)CoT 方式。AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
清华大学提出的
AdaThinking框架。- AdaptThink: Reasoning Models Can Learn When to Think
- 备注:
AdaCoT和AdaThinking出发点几乎一模一样,都可以用下面这个图表示(from adathinking)。
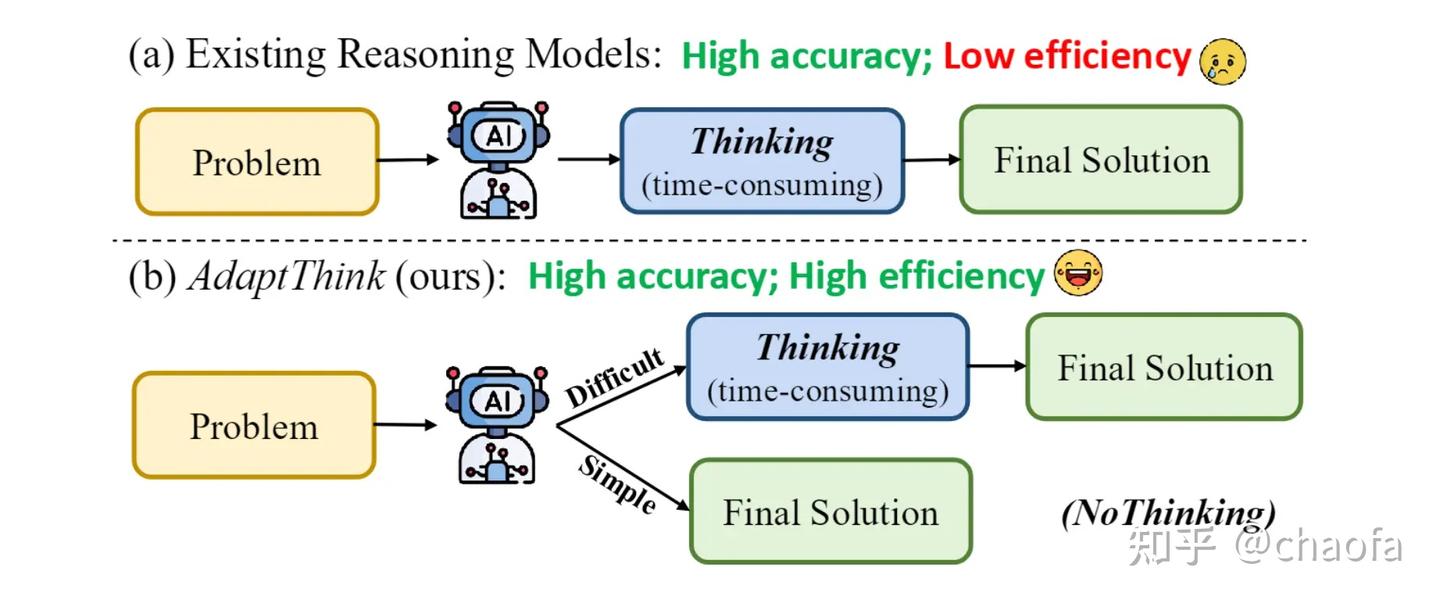
2. 阿里 Qwen3 混合思考
Qwen3 的整体训练流程如下图所示:
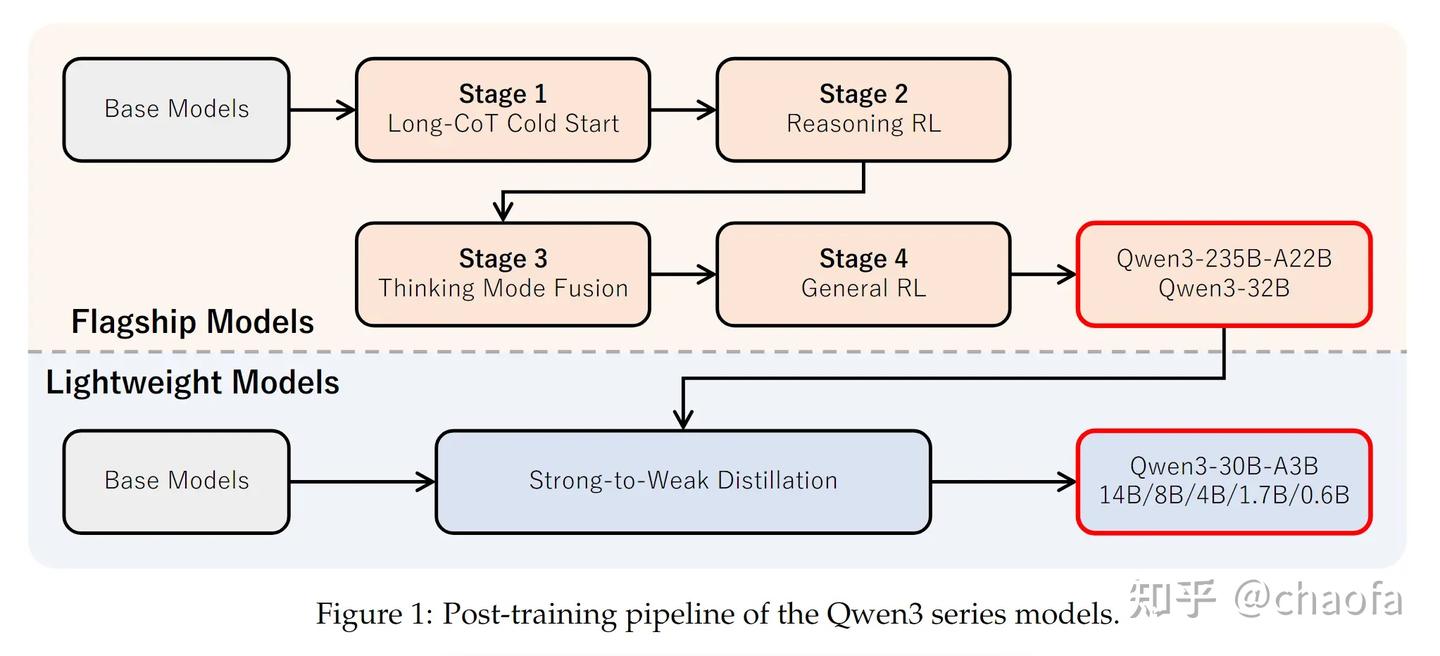
一共有四个阶段,其中思考混合模式(Thinking Mode Fusion)位于第三个阶段,其实也就是对应着 Supervised Fine-Tuning(SFT)阶段。因此很显然 Qwen3 混合思考的能力主要来源于 SFT,这也是区别于另外两篇文章的地方。
首先如果让聪明的读者来做这个事情,可能也能想到要【构造混合思考的训练数据,然后通过 Prompt 指示模型进行思考或者不思考】,因为 OpenChat 在 23年九月份的 OpenChat: Advancing Open-source Language Models with Mixed-Quality Data 就有类似的思想。因此核心就是构造具有思考、以及没有思考的数据。
2.1 训练
2.1.1 (主)SFT 数据构造
构造一个混合思考的 system template,如下所示

如果训练数据需要思考,那么在 user query 后面加上 /think 表示符号,然后模型需要填充 {thinking_content} 内容;而如果不需要思考,则在 user query 后加上 /no_think,就让模型思考标签中的内容变成 <think></think> (要保证 non-thinking 数据多样性)。这样构造出这样的 SFT 数据之后,模型就初步具备了混合思考的能力。
其他细节:thinking 部分的数据,是用 stage 2 中的 reasoning model 从 stage1 中冷启动数据做拒绝采样得到的.
另外还有一个自发涌现出来的能力(Thinking Budget):当模型训练完了之后,我们可以根据用户设置的 max_tokens 手动终止思考过程,当快接近 max_tokens 的时候,拼接一句: Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n</think>.\n\n 然后让模型接着生成,模型就能做最终的回复,并且效果还不错。
2.1.2 强化学习RL
在第 4 阶段通用 R L的过程中,其他数据怎么处理的我们在本文中暂不介绍,感兴趣可以看 Qwen3 Technical Report。我们仅介绍和 Thinking Mode Fusion 相关的。具体是:
前面 SFT 做了模型的混合 thinking 数据训练之后,模型也不一定完全遵循,因此为了强化模型对于 /think 或者 /no_think 指令的遵循,RL 阶段又加了 format-following 的格式奖励。
- user query 中有
/think的时候,模型的回复需要时<think> a lot of thinking</think> final respone - user query 中有
/no_think的时候,模型的回复需要时<think>\n\n</think>\n final respone,注意⚠️:这里的thinkxml 中是没有内容的(只有 \n\n)。
2.1.3 推理
从刚刚的训练数据中,我们也可以推测出模型推理是怎么做的,有两种方式:
- 方式1:手动在 system_prompt 或者 user_query(instruction) 末尾添加
/think或者/no_think标签。这样模型可以自发判断要不要填充思考内容到thinking_content中。 - 方式2:如果你不想模型思考,那么在 tokenizer 的时候设置
enable_thinking=False,那么 Tokenizer template 会主动把用户 query后面设置<think>\n\n</think>\n。
我们用的比较多的是: chat api,但实际上模型只会 predict next token,所以正常的输入是
1
2
3
4
5
messages = [
{"role": "system", "content": "你是 qwen3,你是很有用的助手。"},
{"role": "user", "content": "chaofa用代码打点酱油是谁?。"},
{"role": "assistant": "chaofa用代码打点酱油似乎是一个专注于 LLM 的算法工程师,业余在 B站/YouTube 分享视频~"}
]
然后模型经过 tokenizer 之后,就会变成:
1
2
3
4
5
6
<|im_start|>system
你是 qwen3,你是很有用的助手。<|im_end|>
<|im_start|>user
chaofa用代码打点酱油是谁?<|im_end|>
<|im_start|>assistant(模型从这里开始 predict next token)
chaofa用代码打点酱油似乎是一个专注于 LLM 的算法工程师,业余在 B站/YouTube 分享视频~<|im_end|>
因此如果enable_thinking=False,那么 Tokenizer 之后的输入为.
1
2
3
4
5
6
<|im_start|>system
你是 qwen3,你是很有用的助手。<|im_end|>
<|im_start|>user
chaofa用代码打点酱油是谁?<|im_end|>
<|im_start|>assistant
<think>\n\n</think>(模型从这里开始 predict next token)
如果enable_thinking=True,那么 Tokenizer 之后的输入为:
1
2
3
4
5
<|im_start|>system
你是 qwen3,你是很有用的助手。<|im_end|>
<|im_start|>user
chaofa用代码打点酱油是谁?<|im_end|>
<|im_start|>assistant(模型从这里开始 predict next token)
到这里,我们让模型自发的学会了混合思考的能力,
- 方式1:只不过我们需要手动在
prompt中写上/think或者/no_think来启动或者终止思考。 - 方式2:当模型不加
enable_thinking=False的时候,模型默认思考,加了之后默认不思考。
发现问题没有,模型并不会主动知道什么时候应该思考,什么时候不应该,这都是人在控制的?而下面两篇文章就是就是让模型自己学会【要不要思考】。
3. 字节Seed AdaCoT
再来回顾一个这个图,我们希望模型主动触发思考和非思考的过程,而不是像 qwen3 一样,需要人为控制。
AdaCoT 这里是把是否要输出 CoT(思考过程 Thinking)当做一个多目标帕累托最优的方式。直观解释,我们优化两个目标,分别是 a. 最少输出 CoT,b. 最大化效果,但一个好了之后另外一个就可能变差,那我们就是希望找到某个点,在最小化输出 CoT 的时候最大化模型效果,用公式表示如下:
其中 $P(\theta)$ 是模型得分(最终的评估的分数,比如是否代码是否通过),$T(\theta)$ 是激活 CoT 的次数,因此我们可以设置不同的 $\lambda_{P}$ 和 $\lambda_{T}$ 来得到最大的的值,两个 $\lambda$ 是超参数,在文中实现了四组参数。
3.1 训练
3.1.1 SFT 冷启动
为了让模型能快速知道什么时候应该用 think or CoT,什么时候不该,最简单方式就是造一批数据让模型做冷启动。
首先,找一批数据,用一个额外的模型使用 Prompt 的方式判断一条数据使用 CoT 有没有增益,只要是能遵循指令遵循的 Model 都可以做冷启动数据产生的作用。Example Prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Given a dialogue between a user and an AI assistant , please consider the conversation context and , from the AI assistant ' s perspective , assess the difficulty of answering the user ' s final question according to the following requirements .
< AI assistant ' s system prompt - Start >
{ system_prompt }
< AI assistant ' s system prompt - End >
< Dialogue history - Start >:
{ history }
< Dialogue history - End >
< User ' s final question - Start >
{ last_prompt }
< User ' s final question - End >
## 评估步骤
1. 仔细阅读, 理解问题
2. 评估 question 的难度,xxx
3. 输出需要按照特定的格式
## 评估准则
- 需要深度思考。
- 需要多步才能输出最终的答案
- 需要一个有逻辑的思考
- ....
- 不需要深度思考
- 这个问题很简单,我可以直接回答
- 基本常识
- ...
## 输出格式
仅输出下面两者之一,不要给任何解释:
- 需要深度思考
- 不需要深度思考
用这个 prompt 构造出两种模式的训练数据,最终数据变成两种
有思考的数据。
question+<think>详细的思考过程</think>final response备注:这里的 【详细思考过程】 我倾向于是一个其他的思考模型生成的,也可能是人标注的。但具体怎么来的文章没说
没有思考的数据。
question+<think></think>final answer保持
thinkxml 可以保证回复格式一致性,有助于模型能力保持。
备注:这个是非常有意义的,因为 RL 只是提高 pass@1 score,而不会显著提高 pass@k score,也就是说 RL 只是提高了正确答案出现的概率。因此如果基础模型就不好,RL 效果也会好。
3.1.2 (主)RL 训练
PPO 训练
这里用的是 PPO 算法。因此需要一个 Reward Model,具体的 Reward function 设置如下
\[R(x,r) = R_{\text{base}}(x,r) - \alpha_1 \cdot P_{\text{miss}}(x,r) - \alpha_2 \cdot P_{\text{over}}(x,r) - \gamma \cdot P_{\text{fmt}}(r) \tag{2}\]$x$ 是 user query,$r$ 是 model response,$P$ 都是二元奖励或惩罚,也就是只能是 0 / 1,$P_{miss}(x, r)$ 表示缺少思考,$P_{over}(x, r)$ 表示不应该思考的时候思考了,$P_{fmt}(x, r)$ 是格式奖励。最重要的 $R_{base}(x, r)$ 表示当前回复的质量打分,典型的 Model-based Reward Model。
其他细节并不是很清楚,既然写了是 PPO 算法,那么大概率也是 Follow PPO 优化算法公式,如下:
\[L^{\text{KL+CLIP}}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) A_t,\; \text{clip}\left(r_t(\theta), 1 - \epsilon, 1 + \epsilon\right) A_t \right) - \beta \cdot D_{\text{KL}}\left[ \pi_\theta(\cdot | s_t) \;\|\; \pi_{\text{ref}}(\cdot | s_t) \right] \right]\]其中 $r_t{\theta}$ 是重要性采样比率,表示为:
| $r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \$ |
Selective Loss Masking
模型在训练的过程中,如果处理不当,很可能会陷入到二元境地,比如一直都输出 CoT token 或者一直不输出 CoT token。比如在 【数学类】数据集中训练之后,很可能一直输出 CoT token。这样模型就不能很好的进行探索,坍缩到一个方向去了。
这里的做法也很简单,在 RL 训练的过程中,把 policy gradient 中的 loss 不算所有的 token,而是 mask 掉 <think> 后的第一个 token。这样做有什么好处,我们保持了 SFT/RL 阶段学到的要不要触发 CoT,只是我们 mask 掉了 Loss,通过 Loss 优化控制下一步是否触发 CoT,而不是改变上一步学到的结果。
3.2 实验结论
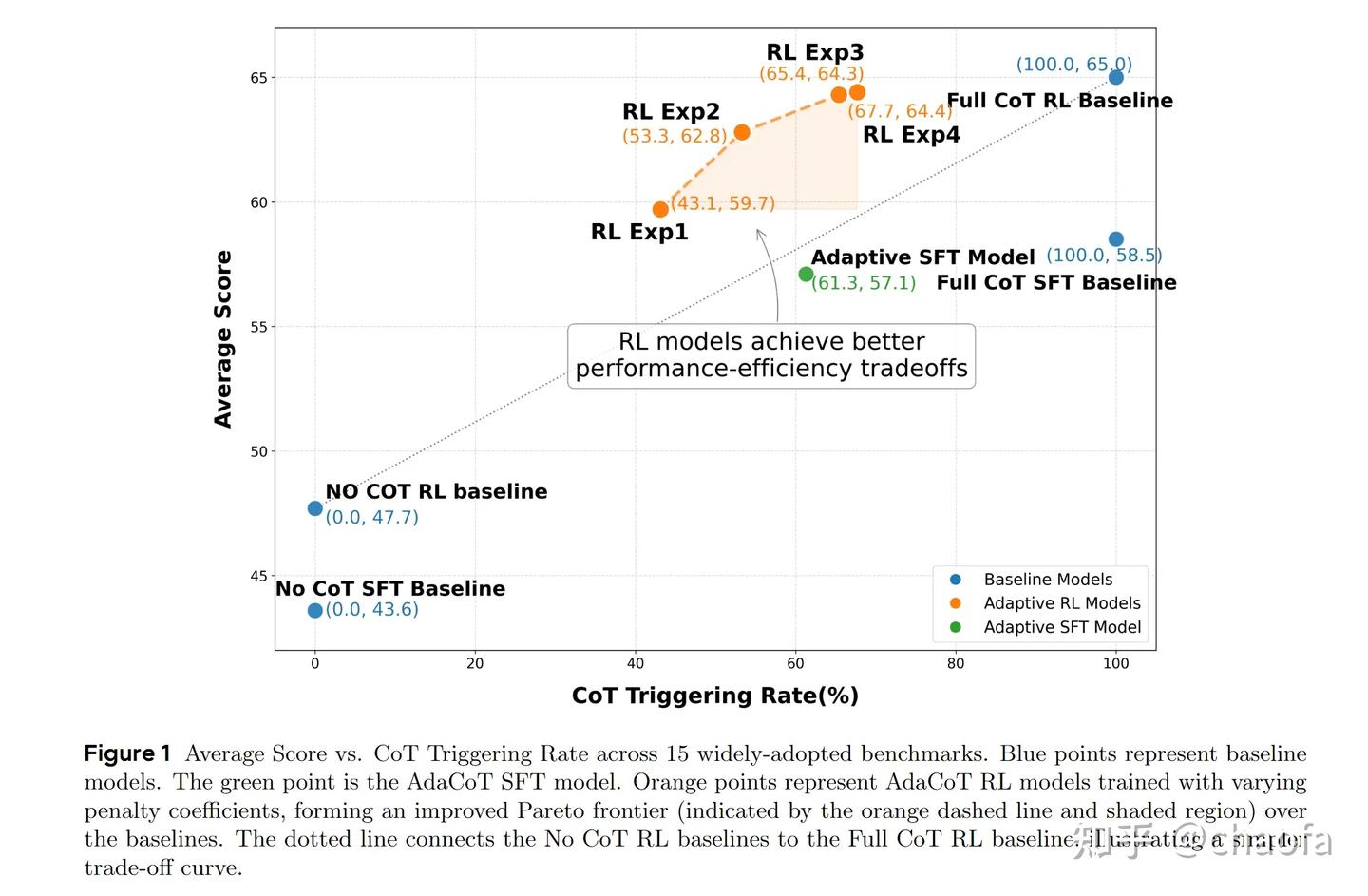
最终的效果也很好,只使用 65% 左右的 CoT 触发率就达到了接近 100% 触发 CoT 的效果。而对于火山的实际调用 CASE 来看,只有 3.18% 的 CoT rate,也就是大部分人的 query 都很简单,没必要 CoT,这在实际工业界还是非常有用的。
3.3 其他
本篇文章出发点很好,唯一的遗憾是细节还是有一些缺失,尤其是比较关键的 Score 设置,比如公式(1)中的 $P(\theta)$ 中 score 的计算方式,以及公式(2)中的 $R_{base}(x, r)$ 是怎么得到的,以及细节是什么。不过作为一篇工业界文章,已经非常好启发性了。而且最重要的是:这篇文章落地了,在火山方舟中就有可以调用的模型。
这篇文章是一个师弟写得,太牛逼了,太佩服了(蹭蹭师弟的热度)
4. 清华 AdaThinking
和 Seed-AdaCoT 这个文章出发点一样,但是清华的这篇 AdaThinking 有一个很好理解的图,有前置的分析,RL 阶段也写得更细节一点(这就是工业论文和学界论文的区别吗?)再把这个图放过来
4.1 前置分析
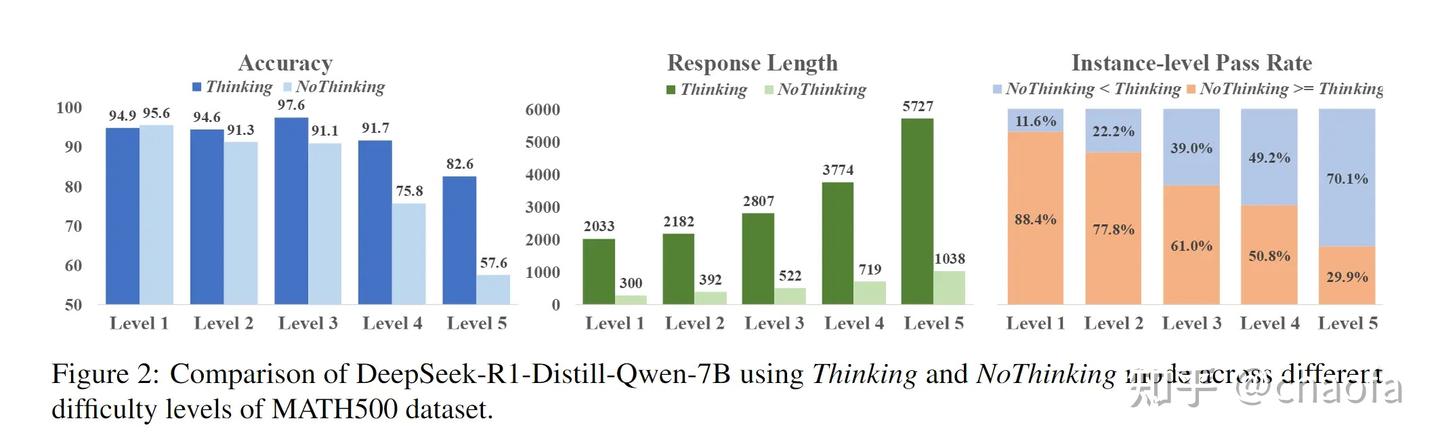
这个图告诉我们:
- 简单问题不需要 CoT 甚至可能带来的更好的效果(左),只有难问题有无 CoT 才会有明显区别。
- 越难的问题越需要更长的思考(中)
- 只有在 Level 5 中 有 Thinking 的模型才明显超过 Non-Thinking(右)
一共有两个part,part1 受限优化问题,part2 重要性采样,整体算法流程如下

4.2 (主)RL 训练
4.2.1 RL for Constrained Optimization Objective
整体的优化目标如下,尽量少的出现 Thinking($y_1 = $ 表示第一生成的词就是 </think> 这样就表示没有思考),但是需要 $R_{\theta}(x, y)$ 要大于 $R_{\theta_{ref}}(x, y)$,后者就是约束。
根据拉格朗日乘数法,可以把约束条件放到优化公式中,最终变成:
\[\begin{align*} \max \mathbb{E}_{x \sim D, y \sim \pi_\theta(\cdot | x), y' \sim \pi_{\theta_{\mathrm{ref}}}(\cdot | x)} \mathbb{I}(y_1 = ) + \lambda (R(x, y) - R(x, y')) \tag{4} \end{align*}\]| 把公式拆一拆,另 $\delta = \frac{1}{\lambda}$ ,$\mathbb{E}{y’ \sim \pi{\theta_{\mathrm{ref}}}(\cdot | x)}$ 下放到期望内部,这样就得到两个期望 |
| 我们用蒙特卡洛采样,可以得到 $\mathbb{E}{y’ \sim \pi{\theta_{\mathrm{ref}}}(\cdot | x)} R(x, y’)$ 近似等于 K 次采样的 Reward 均值,因此我们有 |
因此我们得到最终的优化目标,公式(6)
\[\begin{align*} \max \mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta}(\cdot|x)} \left[ \mathbb{I}(y_1 = ) \cdot \delta + R(x,y) \right] - \bar{R}_{\text{ref}}(x) \tag{6} \end{align*}\]但是我们知道 $\mathbb{I} = y_1=$ 以及 $R(x, y)$ 是不可导的,所以我们用 policy gradient 的方式进行优化,这样也是用 PPO 算法进行优化,具体优化公式为(Without KL):
\[\begin{align*} \mathcal{L}(\theta) = -\mathbb{E}_{x \sim D, y \sim \pi_{\theta_{\text{old}}}(\cdot|x)} \Bigg[ &\min\Bigg( \frac{\pi_{\theta}(y|x)}{\pi_{\theta_{\text{old}}}(y|x)} A(x,y), \\ &\text{clip}\left( \frac{\pi_{\theta}(y|x)}{\pi_{\theta_{\text{old}}}(y|x)}, 1 - \epsilon, 1 + \epsilon \right) A(x,y) \Bigg) \Bigg] \tag{7} \end{align*}\]其中优势函数计算公式为:
$A(x, y) = \mathbb{I}(y_1 = ) \cdot \delta + R(x, y) - \bar{R}_{ref}(x) \$
4.2.2 修改重要性采样
由于开始的模型是 thinking model,所以模型一开始 $y_1 = $ 概率为 0,模型不会直接输出 </think> 终止符。因此我们直接修改 $\pi_{\theta_{old}}$。
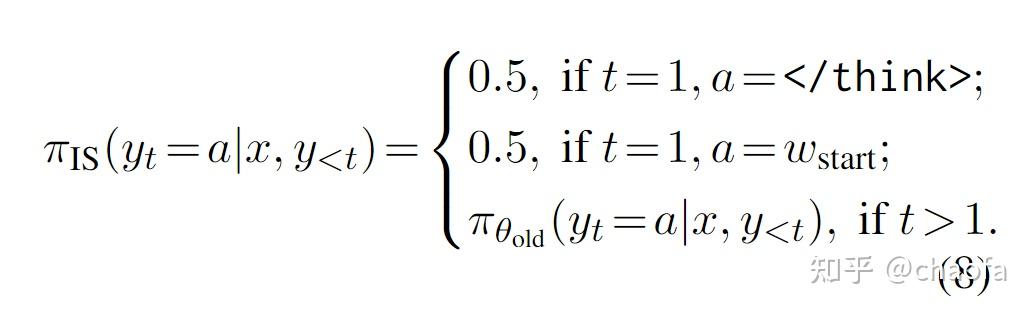
因此最终的 PPO算法公式改成了
\[\begin{align*} \begin{split} \mathcal{L}_{\text{AT}}(\theta) = -\mathbb{E}_{x \sim D, y \sim \pi_{\text{IS}}(\cdot|x)} \Bigg[ &\min\Bigg( \frac{\pi_{\theta}(y|x)}{\pi_{\text{IS}}(y|x)}, \\ &\text{clip}\left( \frac{\pi_{\theta}(y|x)}{\pi_{\text{IS}}(y|x)}, 1 - \epsilon, 1 + \epsilon \right) \Bigg) A(x,y) \Bigg] \end{split} \tag{9} \end{align*}\]从 Loss 上的理解,我们希望同时满足下面两个条件的时候才更新 $\pi_{\theta}$ ,$\delta$ 越大,越鼓励模型不要思考。
\[\begin{align*} \bar{R}_{\text{nothink}}(x) + \delta &> \bar{R}_{\text{ref}}(x), \\ \bar{R}_{\text{nothink}}(x) + \delta &> \bar{R}_{\text{think}}(x). \end{align*}\]4.3 实验结论
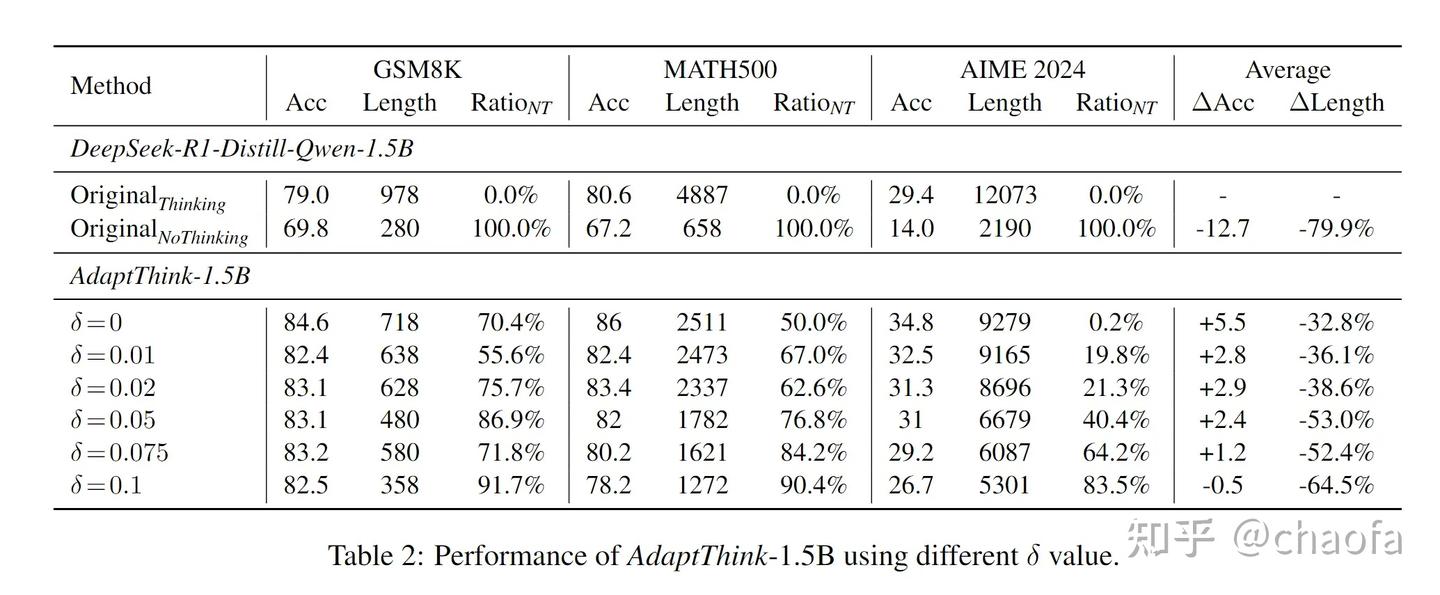
可以看出:accuracy 增加,回复长度减少,刚好符合我的目标。不过这种主实验确实没啥太多信息量,因此效果大概率都是很好的,我们来看一个消融对比实验,下图:不修改重要性采样的时候,只用采用原版的 GRPO 算法。
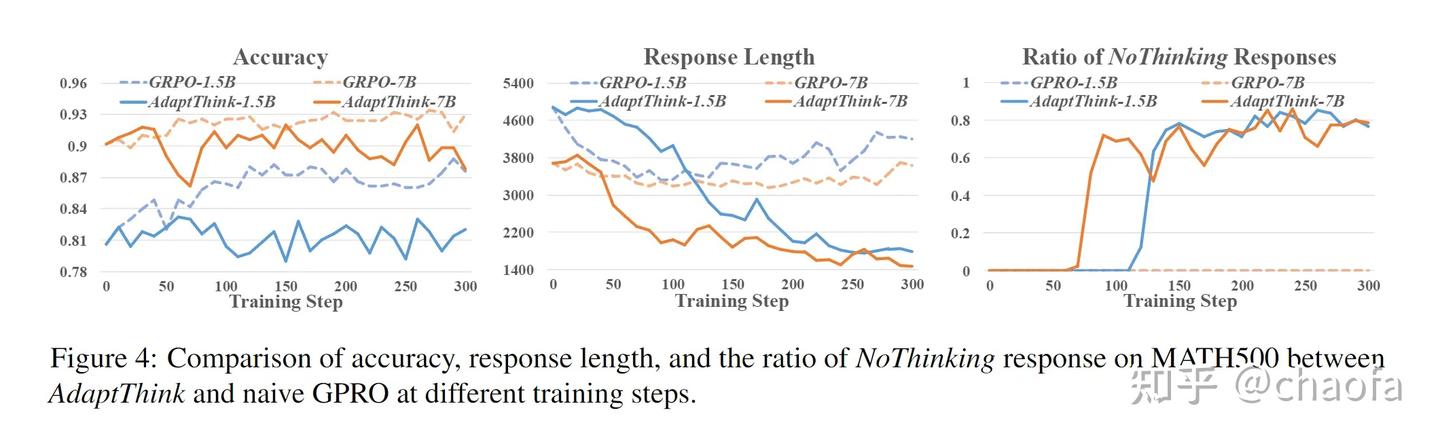
我们可以看出,
- 左。naive grpo 算法学到的其实是 thinking 模式,所以自然效果好一些。(因为第一个 token 出现
</think>的概率几乎为 0 - 中。同理, naive grpo 的学到的是 thinking 模式,所以长度更长。
- 右,同理,触发 thinking 模式的比例更高。
这说明了,我们修改重要性采样是很有必要的。
5. 总结
上面介绍三篇文章如何处理这种混合思考模式。
- Qwen3 主要通过 SFT 训练让模型天然具备遵循【思考、非思考】模式,但是需要人为控制。
AdaCoT和AdaThinking都是让模型自己决定,简单的问题不用思考,复杂的问题可以思考。- 其中
AdaCoT通过把优化目标转换成 Pareto optimization,然后利用 PPO 算法进行优化 AdaThinking也是通过 PPO 算法优化,把问题视为:尽量少触发 CoT 的情况下,新模型的回复大于【旧模型回答】且大于【Thinking 模式模型的回答】。
[DeepSeek-R1]之后,真就全员 RL 啊,什么东西都用 RL 来搞一遍~ ok, RL is all we need~