「Paper Reading」 LLM RLHF 2024论文(三十九)FoT
LLM RLHF 2024论文(三十九)FoT
论文标题[Forest-of-Thought]: Scaling Test-Time Compute for Enhancing LLM Reasoning,原文,发表于ICML 2025。
LLM reasoning经常使用思维链(CoT)或思维树(ToT),来分解问题,增强推理,这种方法通常只进行一次推理过程,可能无法重新处理有缺陷的路径,从而影响准确性。为了解决这一限制,本文提出了思维森林(Forest-of-Thought, FoT)的学习框架,整合了多个推理树,利用集体决策来解决复杂的推理问题。FoT采用[稀疏激活策略]来选择最相关的推理路径,此外,还引入了一种动态自我修正策略,实现实时的错误修正,来优化资源的使用。实验结果表明,FoT框架显著增强了LLM的推理能力,能够以更高的精度和效率解决复杂任务。
背景
大模型应用中的数学计算、逻辑推理之类的任务可以用CoT的方式,将数学推理任务step by step地拆解,并且进一步将其建模成树的结构(ToT),并且使用MCTS的方式来增强inference的效果。
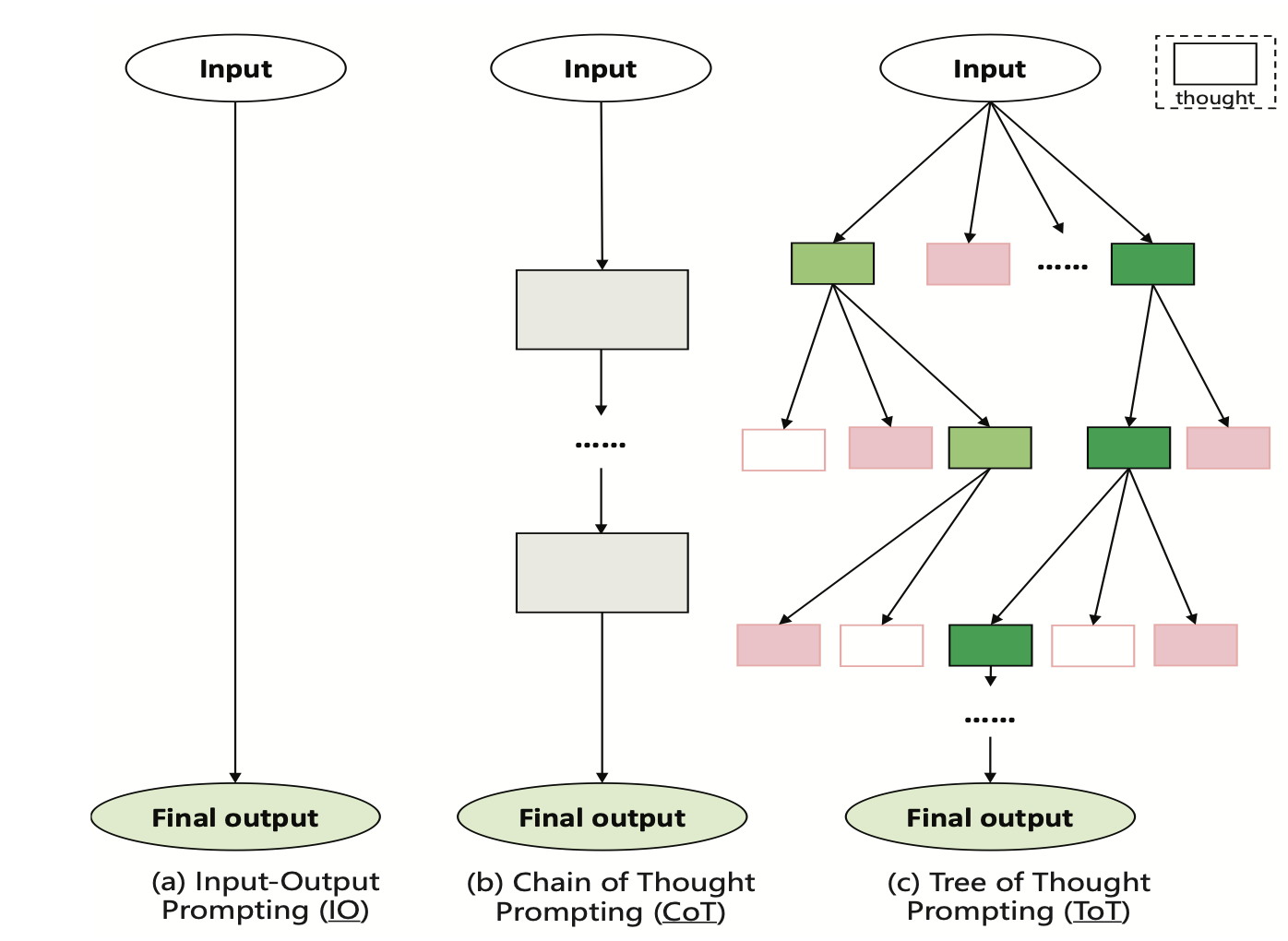
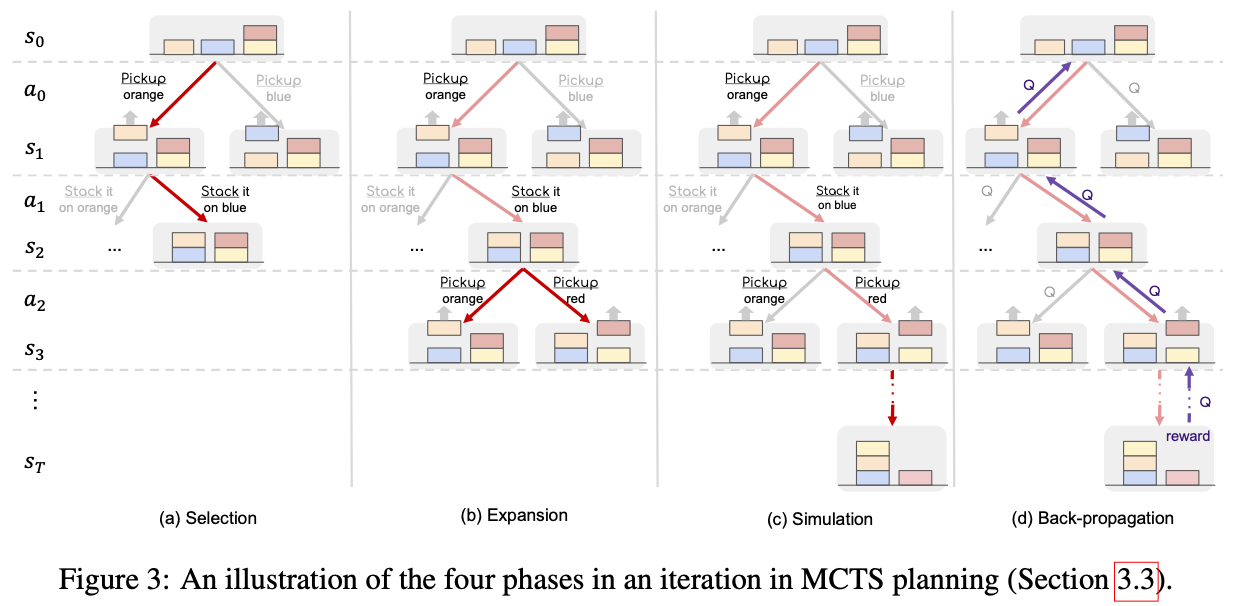
其中,ToT结构经常结合MCTS算法使用,MCTS是一种搜索算法,它利用蒙特卡洛模拟来进行搜索MCTS 维护了一个搜索树,这个搜索树记录了之前的搜索过的(状态动作序列)轨迹和相关统计信息(平均回报与访问次数),从而可以兼顾探索(explore)和利用(exploit),以较低的开销搜索到较好的结果。
算法
现有的ToT类方法将复杂问题分解为更简单的子问题来进行推理。然而,在分解问题的过程中,可能会由于中间步骤出错,从而导致最终答案不正确。但这类方法一旦完成了一条推理路径,如果初始路径存在缺陷,往往会过早放弃掉路径而没有充分地探索,从而损害了解答的准确性。
因此,本文提出FoT算法,通过引入多个推理树进行独立决策,并采用稀疏激活策略来过滤关键树的结果,构建思维森林来增强LLM的推理能力。FoT利用集体智能来弥补个体的不足,从而提高模型从多个角度进行推理的能力。如图所示:
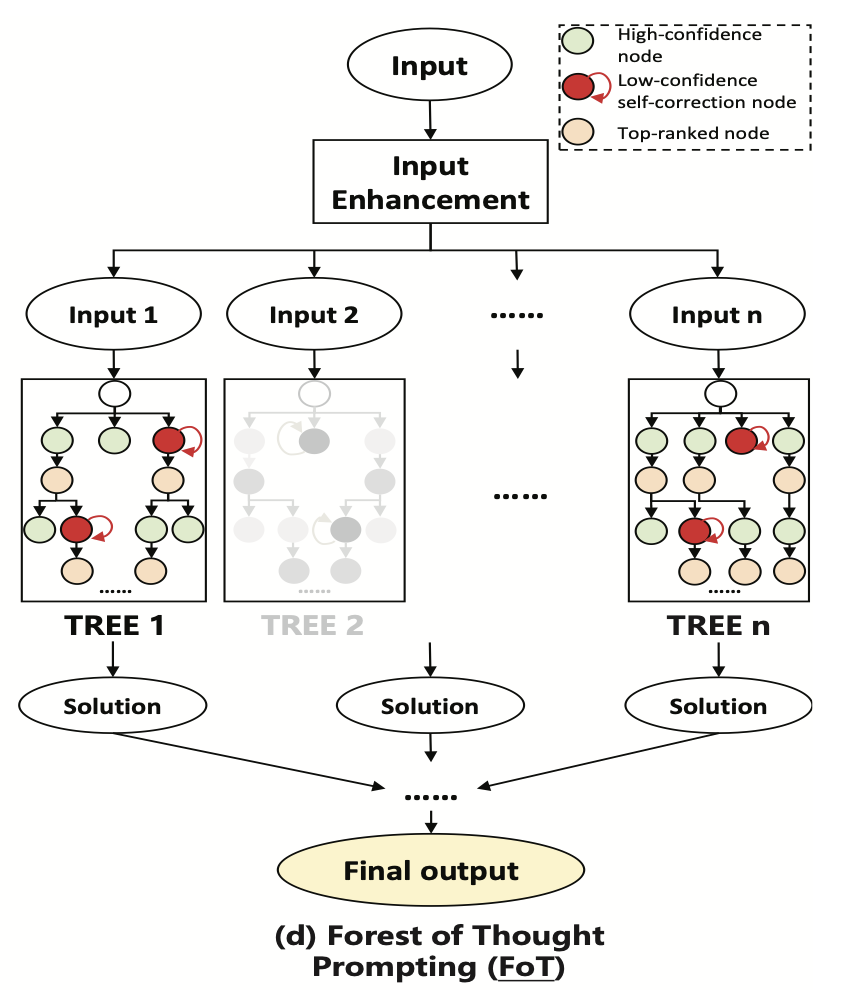
FoT算法会使用n棵推理树进行决策,每棵树的根节点使用了数据增强,并且在推理过程中设置了稀疏激活函数,决定每棵树是否被激活:

对于每棵推理树,每一层选择评估分数最大的节点,进行后续的推理,扩展后续的子节点。如果一层的节点都不能输出有效值,会停止扩展这一棵树,即稀疏激活值设置为0:
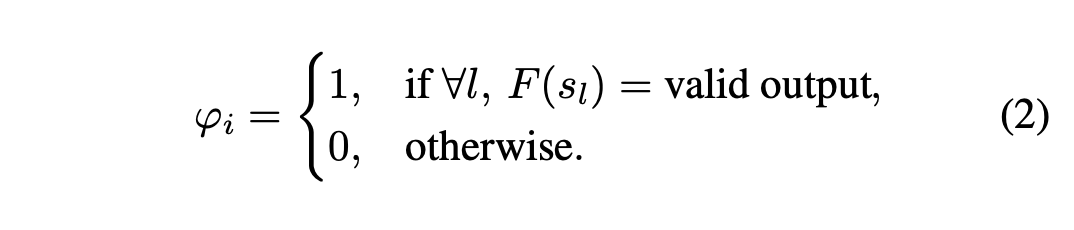
后续过程中,只有激活的树会参与最终的决策。
此外,FoT还使用了数据增强的方式,从公开可用的数据集中收集和构建了一个知识库,以支持模型的推理过程:
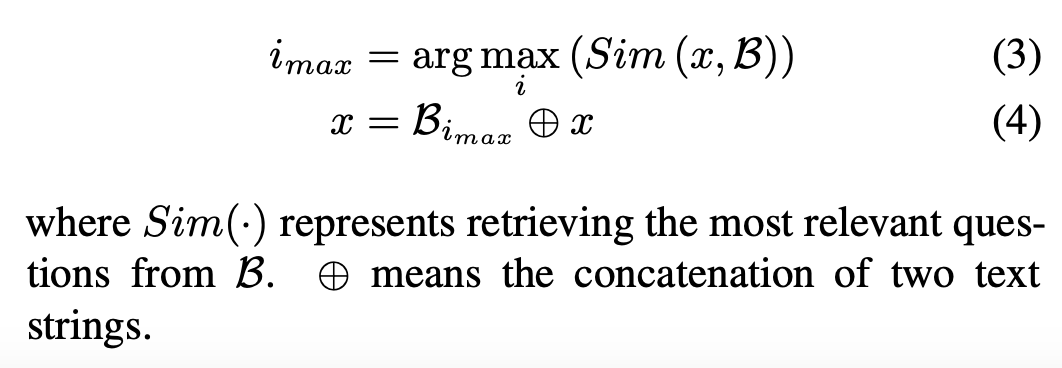
FoT还采用了提前终止的搜索方式,一旦找到解决方案,搜索就会立即停止,避免冗余计算,一旦某个分支与ground truth匹配,也会停止对无关路径的进一步探索,提高整体效率。
此外,FoT还使用了[动态自我纠正]的策略,通过动态评估每个推理步骤,特别是通过监控预测的logits分数来评估推理结果的质量。当模型的分数低于预定义的阈值时,会触发校正机制,以及时检测和修正错误。FoT还融入了预定义的数学规则,通过将这些规则嵌入到推理框架中,模型可以在检测到错误时立即进行修正。例如,在[24点游戏]中,模型可以验证输出中的剩余数字是否来源于输入数字,从而实现快速的错误检测和修正。
动态自我纠正的具体流程如下:

在每棵树都给出结果后,FoT算法会经过majority voting和专家评估,以确定最佳答案。对于复杂的推理任务,如果大多数树产生的结果不一致,会有一个LLM专家比较不同树的推理过程和结果,并基于其专业知识和经验做出最终决策。
FoT的完整算法流程如下:

实验
在24点游戏、GSM8K和MATH等任务上进行实验,使用Llama3-8B-Instruct、Mistral-7B和GLM-4-9B等模型作为基础模型,对比CoT,ToT等算法。
24点上的实验结果:
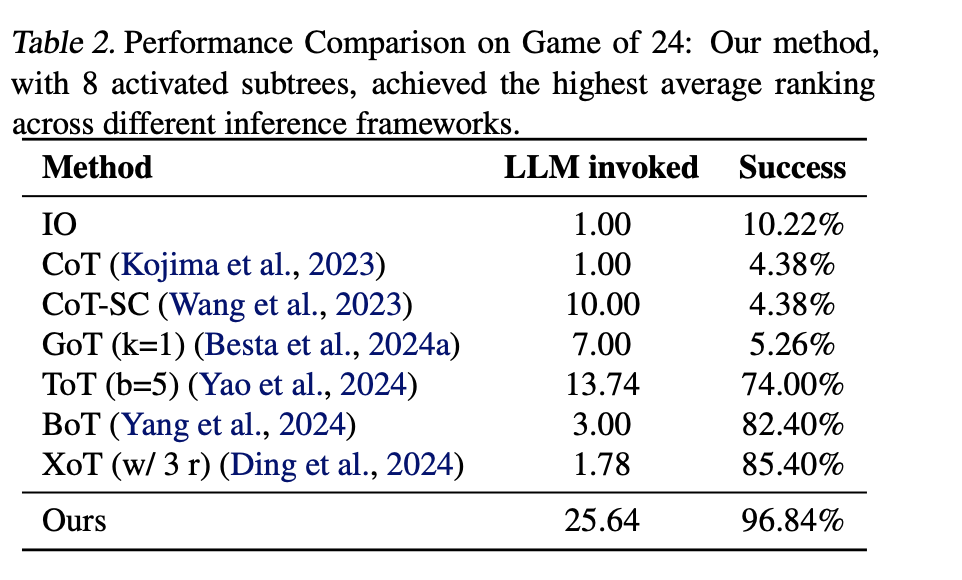
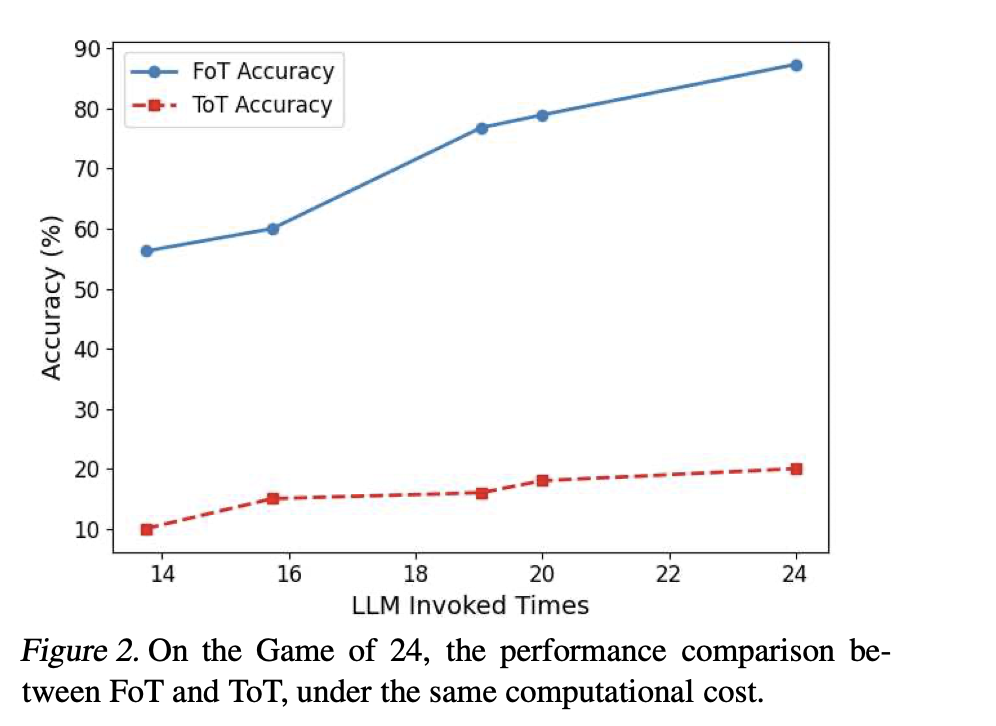
FoT对比ToT:
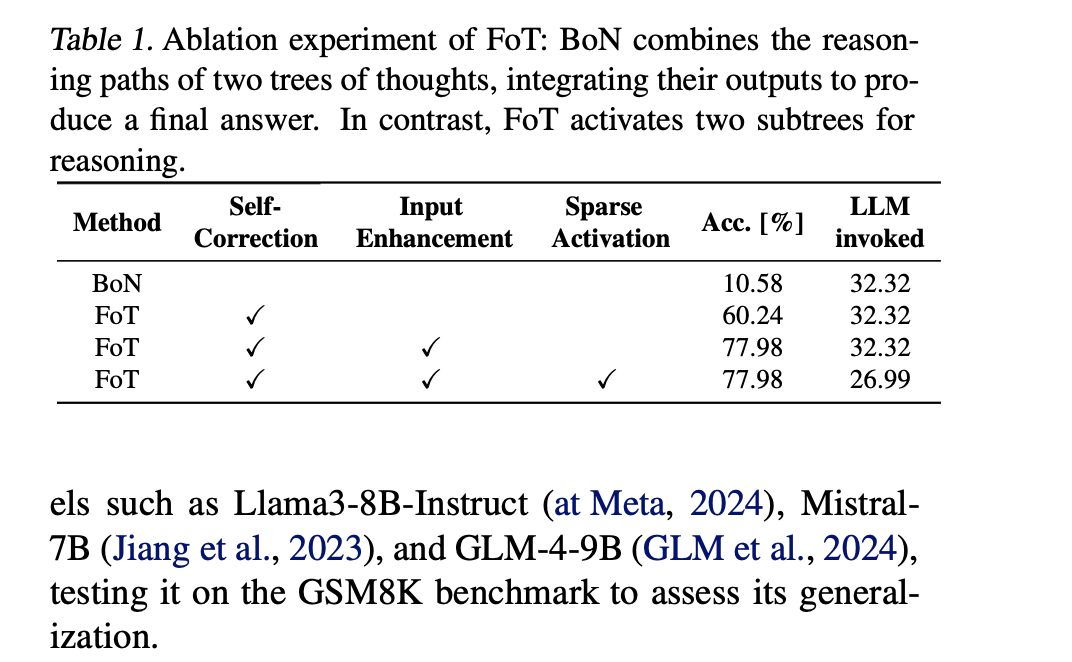
消融实验的结果表明了各个添加模块的有效性:
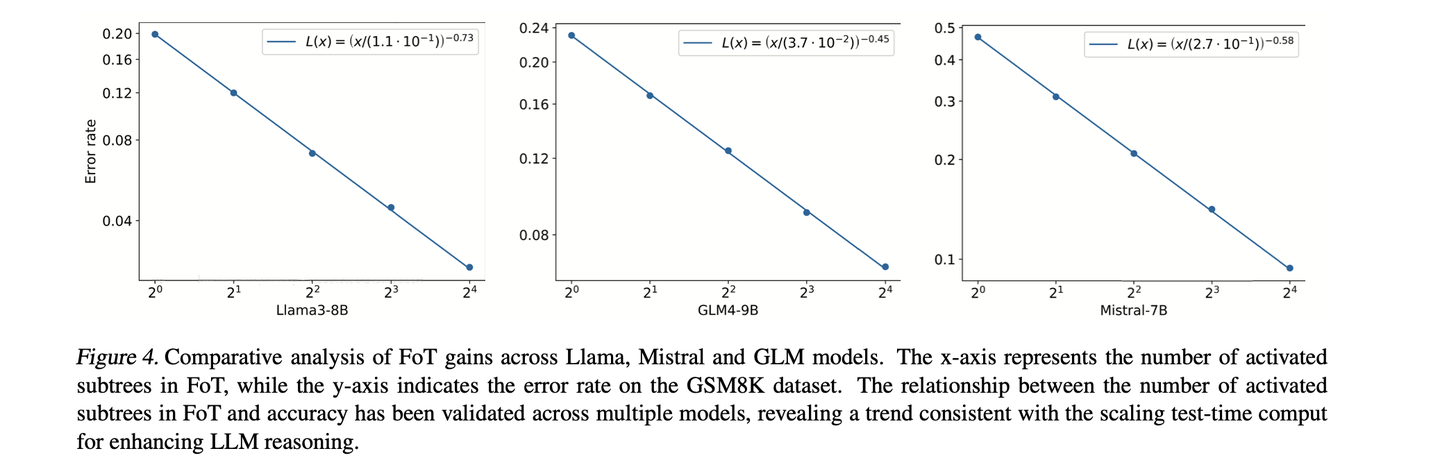
GSM8K上的实验结果对比:
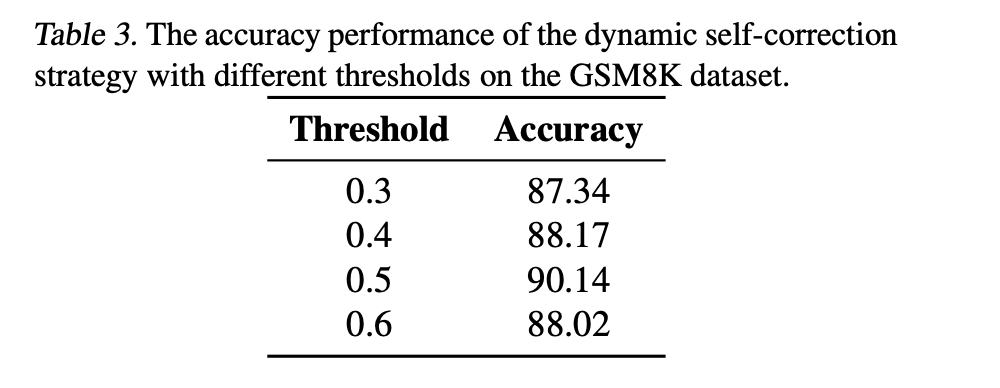
动态自我纠正阈值的对比:
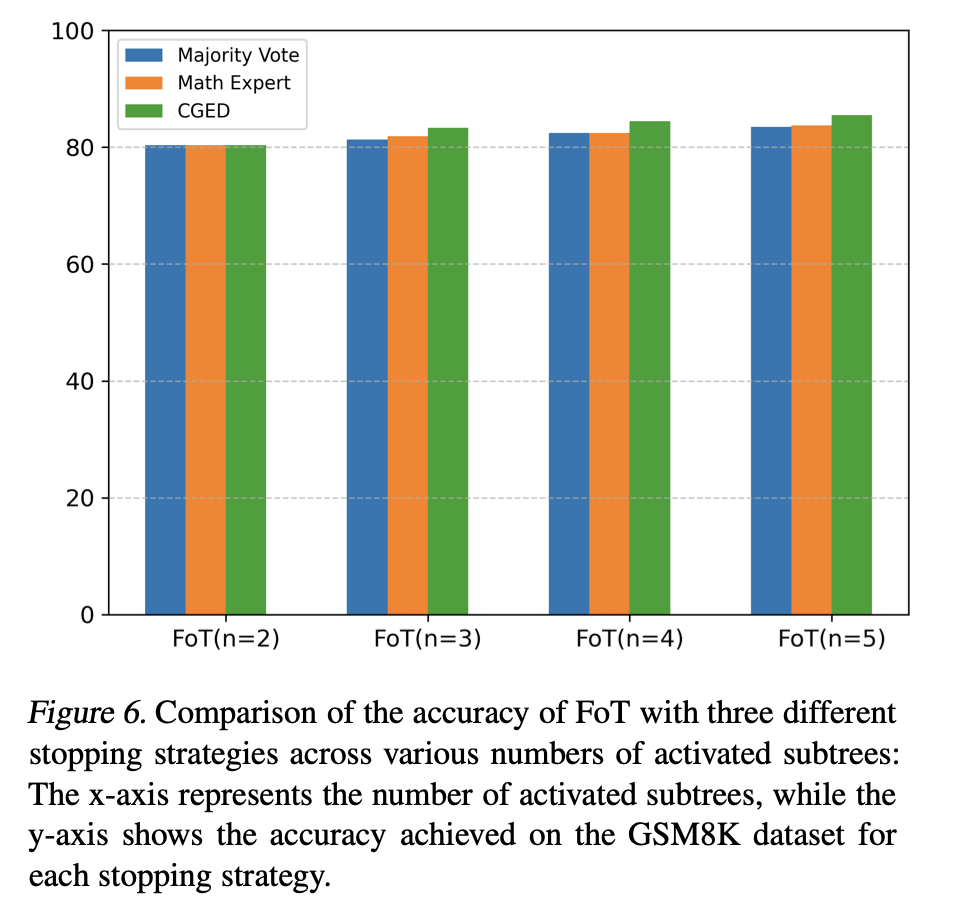
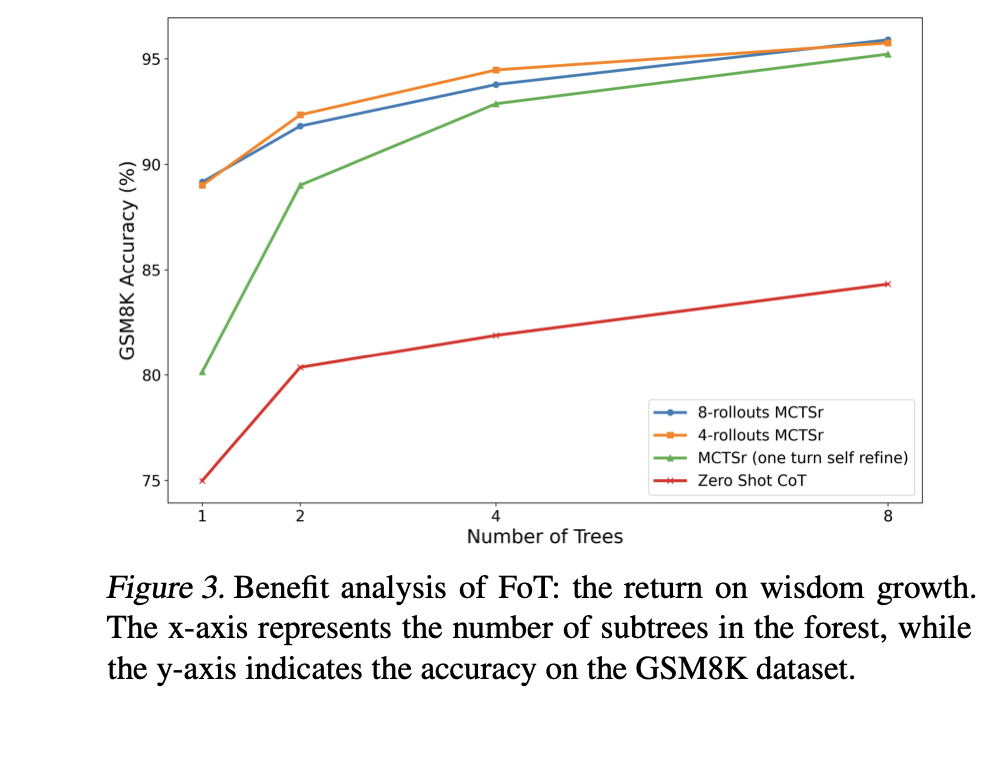
Scaling law的实验,随着FoT中激活的子树数量增加,模型准确率显著提高:
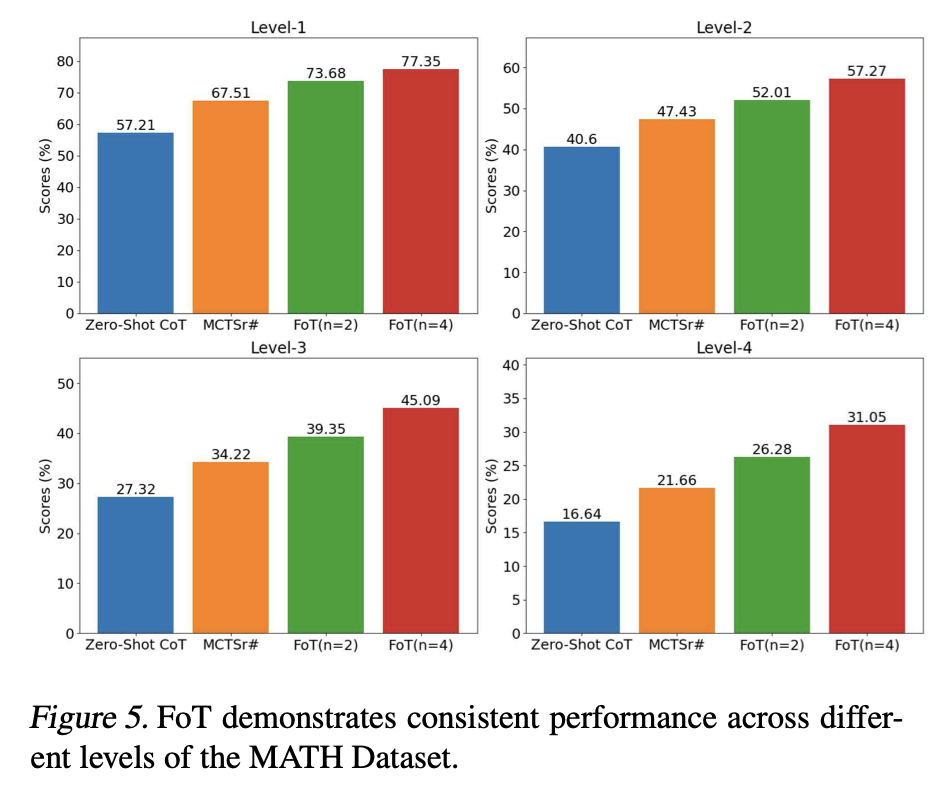
Math任务上的实验结果:
对比不同决策策略的效果,多数投票,专家LLM,和FoT使用的二者结合的方式: