Mysterious GPT O1
【o1猜想】LLM inference scaling:MCTS
1 .简介
[OpenAI] o1用了 [Chain-of-thought]做inference,去训练[self-play] RL
- o1提到要more [reinforcement learning] (train-time compute) 和with more time spent thinking (test-time compute)。
- 在inference层面,test-time compute的scaling是未来发展的趋势,可能会比单纯地扩展模型参数更经济有效。
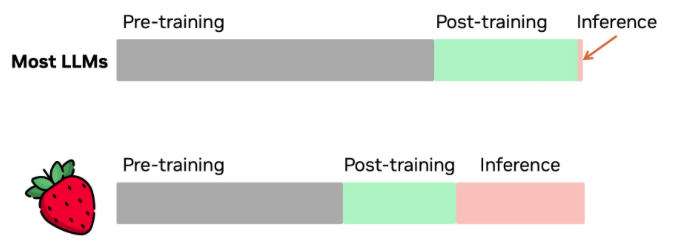
论文Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters [1] 提到,inference的scaling有两种形式:
- refining the proposal distribution:在输入层面修改分布,self-critic / self-refine/ revisions,让模型不断修改自己的答案,串行
- searching against a verifier :在输出层面修改分布,inference阶段利用[PRM],以Best-of-N/BFS/DFS/MCTS 等搜索方式来提升 reasoning 效果,并行
这里主要介绍searching against a verifier的方案,流程如下:
- SFT训练policy model
- 训练PRM,reward model / value model
- 迭代进行以下流程:
- 利用policy和reward/value进行MCTS等搜索方法推理,收集数据
- 用数据去SFT/DPO/PPO 更新policy和reward model/value function
2.TOT
论文Tree of Thoughts: Deliberate Problem Solving with Large Language Models [2] 给出了ToT的概念:
- 将CoT建模为树状结构,之后可以用BFS/DFS/MCTS等search方法增强推理能力。
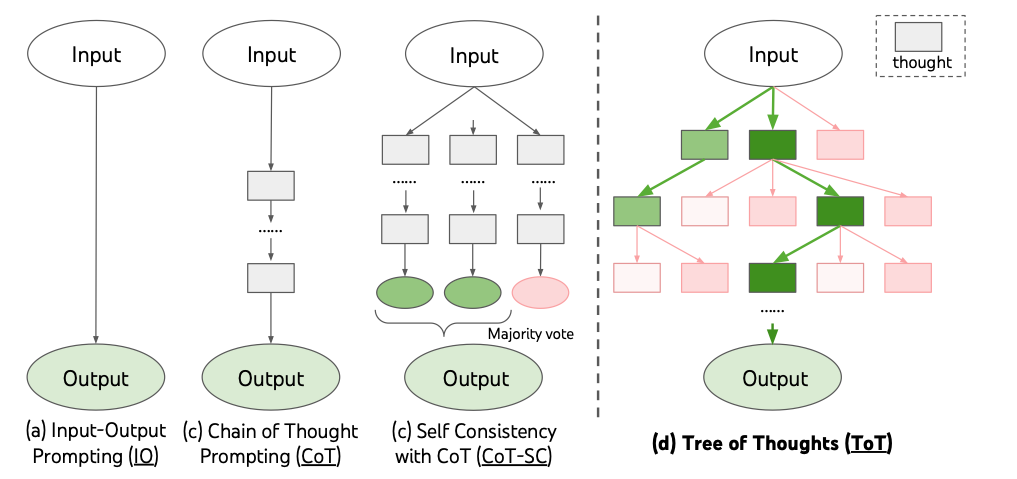
树的节点划分可分为sentence-level和token-level(论文AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training [3] 的划分方式)
sentence-level:将每个chain-of-thought reasoning视为一个节点,这也是ToT/RAP论文中所采用的方式。sentence-level动作节点提供了一个相对较浅的树(深度低),简化了树搜索过程,但是由于生成sentence的可能较多,需要限制树的宽度,也就在搜索空间上有所限制。
token-level:就是以每个token作为树的一个节点。对于token级动作节点,虽然它可以消除搜索空间上的限制,但增加了树的深度,使搜索变得更加困难。
3.训练PRM
论文Let’s Verify Step by Step [4] 中提出PRM的概念
- Outcome-supervised Reward Models:奖励模型只对LLM输出的结果打分
- Process-supervised Reward Models:奖励模型对LLM输出结果的每一步打分
PRM可以给出response中的哪些部分是错的,给出更精准的反馈。

PRM通过对每一行打分,有效定位出错误位置,如果过程中有错误,假设最终Answer是对的,整个LLM输出也会是低分,有效增强模型对于中间过程的学习能力。
训练PRM有几种方式:
用人工标注的数据训练
论文Let’s Verify Step by Step中对每一步都分配一个正、负或中性的标签,正标签表明该步骤是正确的和合理的。负标签表明该步骤要么不正确,要么不合理。中性标签表示歧义。可以推迟关于如何处理歧义的决定,可以将中性标签视为正面或负面。再有了人工标记的数据之后,再监督学习的方式训练PRM。

- 也可以人工标注出二分类的数据训练:

- 根据后续路径做hard estimation或soft estimation(论文Math-shepherd: A label-free step-by-step verifier for llms in mathematical reasoning)

- 用LLM判断每一步是否正确(论文Reasoning with Language Model is Planning with World Model [5] 提到)
学value function(the expected future reward)
- AlphaZero等论文中会利用value function来进行MCTS。
- RL中的value function表示在当前状态对未来reward的期望。通常用神经网络去计算value。
- value function可以在search的过程中直接用reward model更新,也可以先离线学一个value model(论文AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training)

有了PRM之后,就可以用search方法来增强推理,search的方法包括best-of-n/BFS/DFS/MCTS等方式。后续主要介绍MCTS。
4.MCTS
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一种搜索算法,它利用蒙特卡洛模拟来进行搜索MCTS 维护了一个搜索树,这个搜索树记录了之前的搜索过的(状态动作序列)轨迹和相关统计信息(主要是平均回报与访问次数)。
MCTS的特点是可以兼顾探索(explore)和利用(exploit)
- MCTS不需要对全部的游戏树进行搜索,而是通过统计信息来指导搜索过程,使得它特别适合于搜索空间巨大的问题。
- 可以在大状态空间和大动作空间的问题中找到高质量的解,而且其性能可以通过增加模拟的次数来提高
- 在大状态空间和大动作空间中执行时,MCTS 往往需要大量的计算资源。
MCTS可以分为四步:
- 选择(Selection):从根节点往下走,根据规则(例如UCB/TUCB)选一个节点,直到一个未扩展的节点
- 扩展(Expansion):对当前节点进行展开,获取它的子节点,并随机选择一个节点扩展
- 模拟(Simluation):从这个节点Rollout到终止状态,得到reward
- 回溯(Backpropagation):把Rollout的结果加到它的所有父节点上
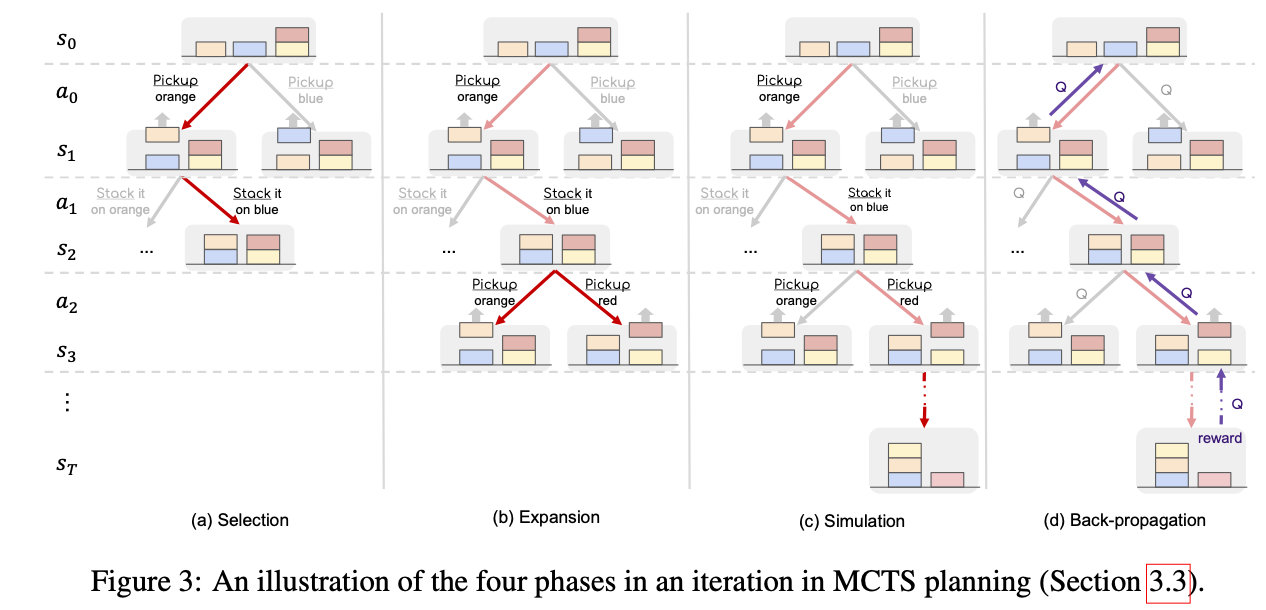
选择:通常根据UCT/PUCT/…等公式选择值最大的节点。综合考虑利用(第一项)和探索(第二项)。V/Q表示对节点的评估值,N表示节点的访问次数。
UCT公式:
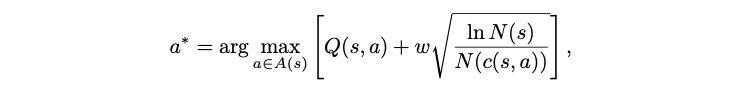
- PUTC公式:

选择操作会不断进行,直到叶子节点。
- 扩展:对当前节点进行展开,获取它的子节点。通常会获取所有的子节点,然后再随机选择一个节点进行后续操作。对于LLM,没法获取到所有的子节点,可以人工规定树的宽度。
模拟:
- 如果是标准的MCTS算法,会从该节点rollout,不断生成,一直到终止状态。
如果是类似于AlphaZero论文等优化过的MCTS算法(论文AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training中提到的MCTS-alpha/MCTS-rollout),不会直到终止状态,而是扩展了之后用value function进行评估,然后就可以将value值回传。
- 回溯:将rollout的结果/value评估出的结果加到所有父节点上。同时访问次数+1。
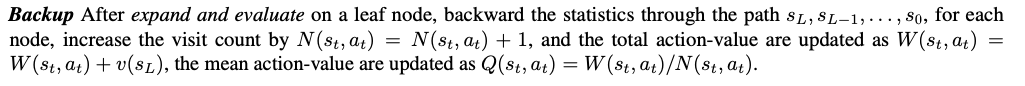
MCTS过程会迭代若干次,在达到预定的MCTS迭代次数,会终止算法并从构建的树中选择最终的推理轨迹。选择的方式可能多种多样:
- 从根节点开始,迭代地选择具有最高value值的动作,直到到达终端。
- 直接从产生最高奖励的迭代中选择路径,
- 或者选择访问次数最多的叶节点(以及相应的根到叶路径)
5.迭代训练
- RAP / ToT论文只增强inference的过程,没有额外再用推理出的数据训练。
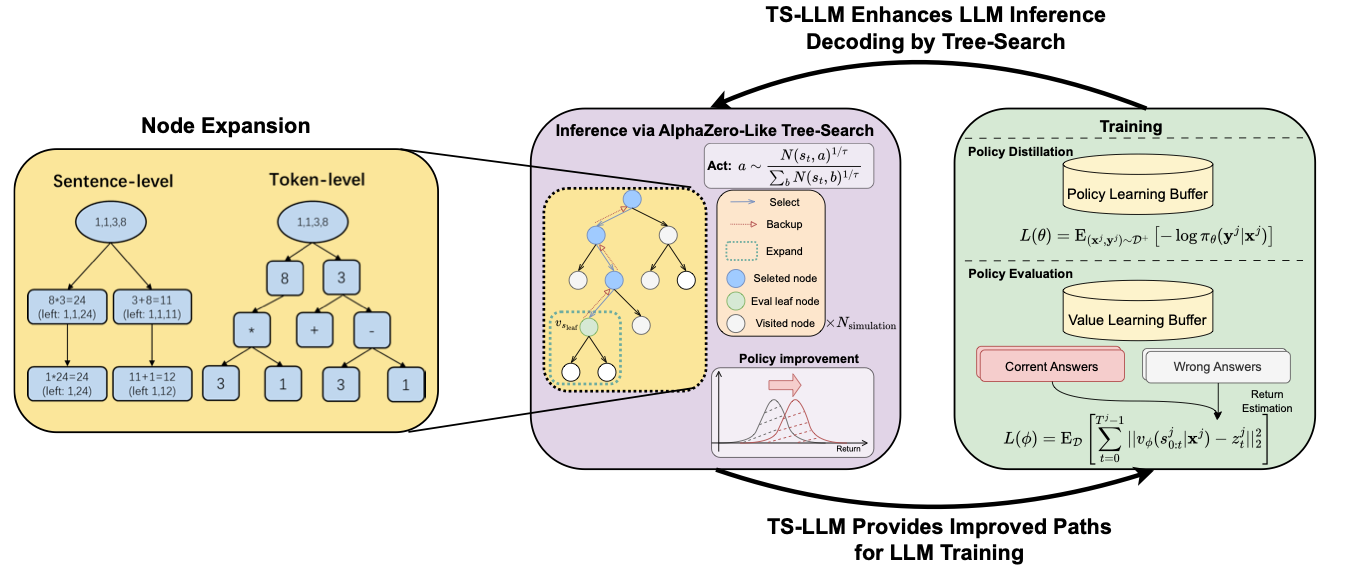
TS-LLM(AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training)会利用迭代更新policy和value/reward:
- 筛选MCTS采样出的positive数据,SFT更新policy
- 用所有MCTS数据去更新value/reward

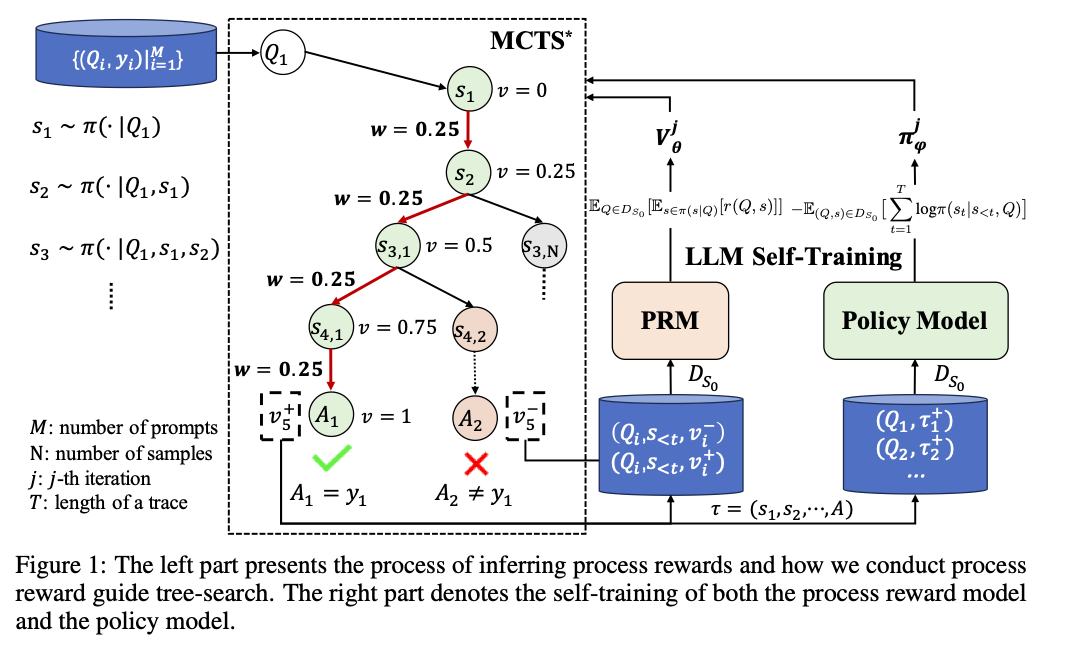
ReST-MCTS* [6] 也会迭代更新policy和value:
- 正样本SFT更新policy
- 正负样本更新PRM
- 论文Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning [7] 收集每一个step的正负样本,训练DPO
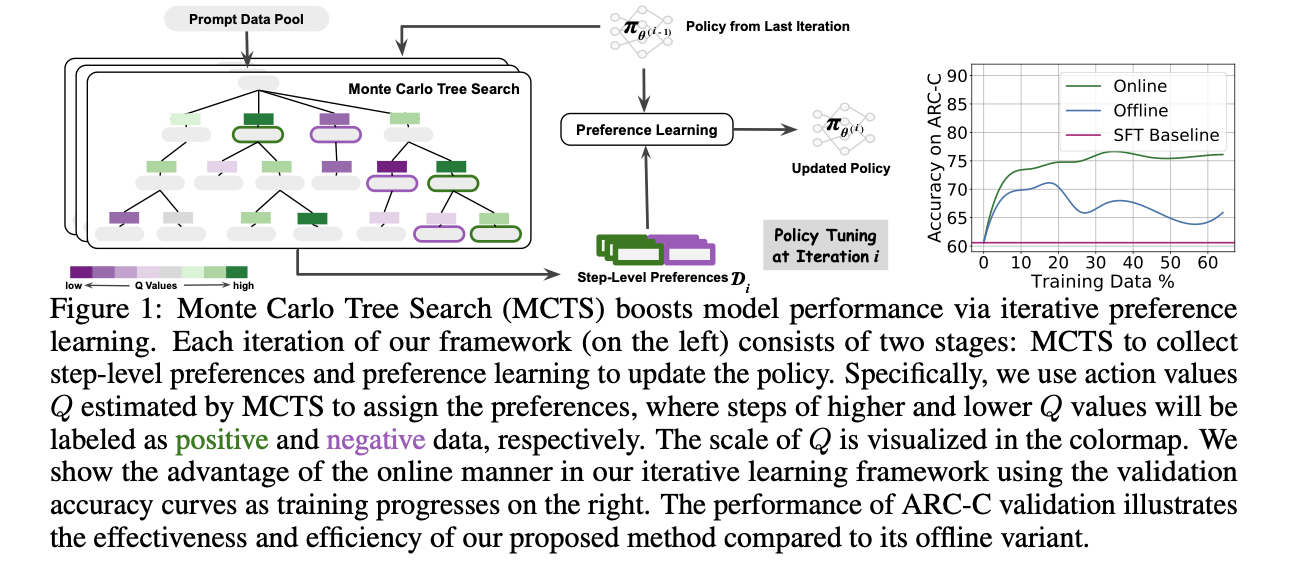
- 迭代进行MCTS搜集数据和用数据更新策略的过程:

- 训练DPO的时候会根据访问次数N加权:

6.总结
目前o1所用到的技术尚不可知,但大体上离不开inference scaling/ scaling test-time,self-play RL,CoT/ToT,MCTS,self-critic/self-refine等方向。其中MCTS类的搜索算法在AlphaGo和AlphaZero时代表现出了强大的能力,又可以很好地与RL算法相结合,应用到RLHF的过程之中,是很有潜力的研究方向。
7.参考文献
[1] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
[2] Tree of Thoughts: Deliberate Problem Solving with Large Language Models
[3] AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training
[5] Reasoning with Language Model is Planning with World Model
[6] ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
[7] Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning